ソブリンAIとは何か──製造業が自社データと技術ノウハウを守るための完全ガイド【2026年版】

「この生産データ、クラウドに上げても大丈夫ですか?」——ある大手製薬メーカーのR&D担当者に、初回の打ち合わせで高い頻度で聞かれる質問があります。
2026年、AIを使いたいという意欲は製造業の現場でも着実に高まっています。ただ、同じ温度感で高まっているのが「データを外に出していいのか」という不安です。ChatGPTやClaude.aiに業務内容を入力している現場担当者がいる一方で、情報システム部門はその実態をつかめていない——この構図が、多くの製造業で静かに問題になっています。
この記事では、「ソブリンAI(Sovereign AI)」という考え方が製造業においてなぜ重要なのか、そして中小企業でも現実的に取れる対策は何かを、私たちAI-PathがFDEとして現場で向き合ってきた経験を交えてお伝えします。
ソブリンAIとは何か——「データ主権」を持ったままAIを使う
ソブリンAIとは、AIの利用にあたって、データ・計算資源・モデルを自国や自社の管理下に置くという考え方です。「ソブリン(Sovereign)」は本来「主権」を意味する言葉で、AIにおいては「誰がデータとインフラを支配しているか」という問いに直結します。
2025年後半から2026年にかけて、この概念が日本企業の間でも急速に注目を集めるようになりました。背景には3つの動きがあります。
1つ目は地政学リスクの現実化。米中間のAI規制・輸出管理が強化されるなかで、海外クラウドへの依存が経営リスクとして認識されるようになりました。
2つ目は経済安全保障推進法の施行と運用の本格化。国内の基幹インフラや先端技術企業に対して、データの保管・処理場所についての規制が強化されています。
3つ目はAIの業務利用が広がったことで、機密データがAIに流れ込む経路が増えたこと。以前は「AI利用」と「機密データ」は別の話でしたが、業務でAIツールを使うようになったことで、両者が交差する場面が日常的に生まれています。
ソブリンAIの実現には「データ」「計算資源(GPU)」「モデル」の3層すべてを国内・自社管理下に置くのが理想ですが、現実には段階があります。私たちが現場で提案しているのは、完全な自社運用ではなく「どの層をどこまで守るか」を業務の機密レベルに合わせて設計するアプローチです。
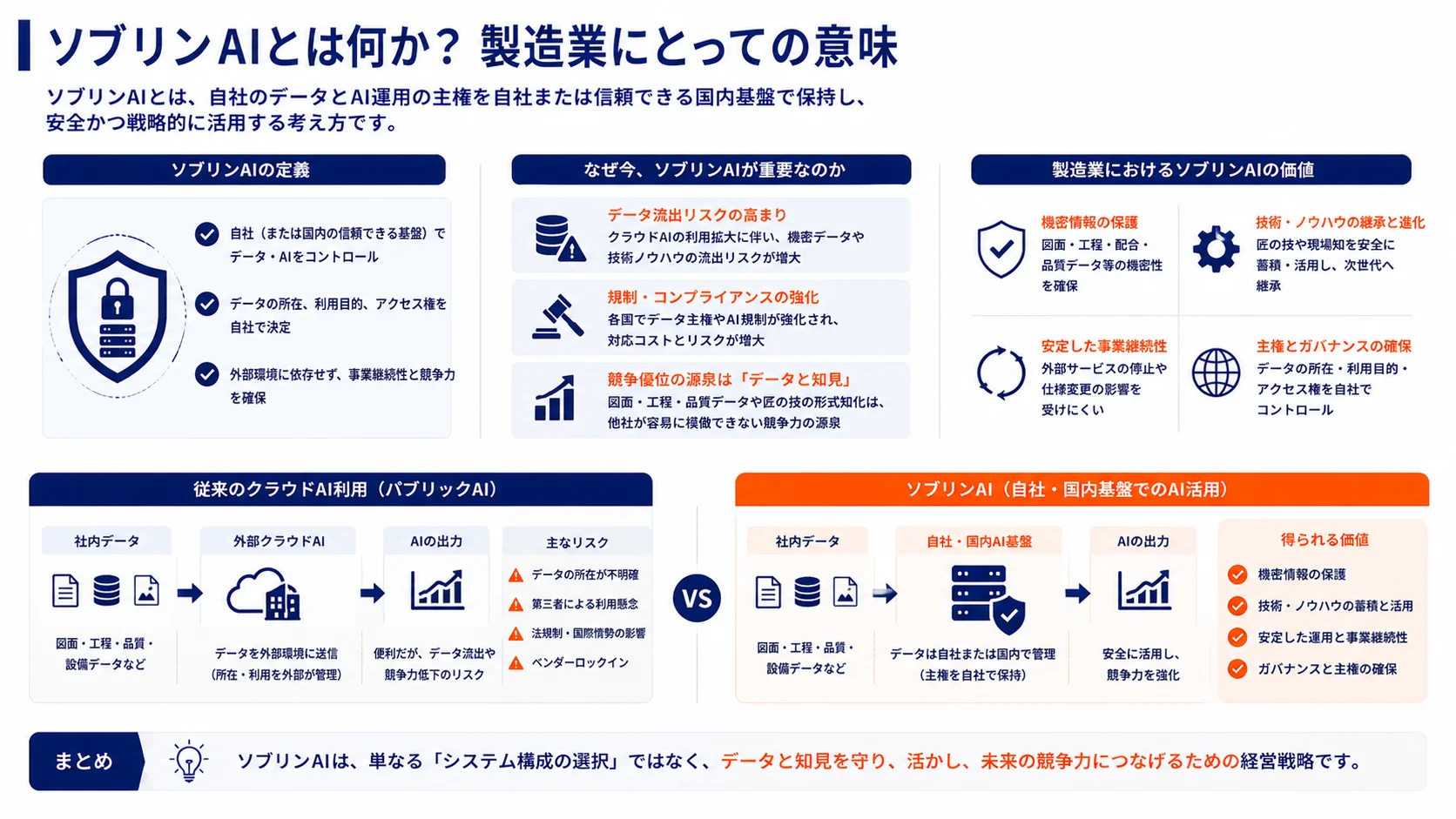
製造業こそソブリンAIが必要な理由——図面・工程・匠の技が持つ価値
ソブリンAIの議論は国家戦略や大手IT企業を中心に語られることが多いのですが、私たちが現場で感じているのは、製造業こそソブリンAIが最も必要な業種のひとつだということです。
理由は、製造業が扱う情報の性質にあります。
図面・設計データは、企業の競争力の源泉そのものです。金型の形状、加工公差、素材の配合比率——こうした情報は長年の技術蓄積の結晶であり、一度流出すれば模倣品が作られるリスクがあります。大手クラウドAIにこれらを入力することは、意図せず海外のデータセンターにそのデータを送ることを意味します。
工程データも同様です。どの工程でどのパラメータを設定すると品質が安定するか、という生産ノウハウは、工場が何十年もかけて積み上げてきたものです。品質管理AIの構築のためにこのデータをクラウドに上げることが、長期的に見て安全かどうかは慎重に考える必要があります。
匠の技・暗黙知もAI化の対象として注目されていますが、熟練工の技術を言語化・データ化すればするほど、それが機密情報として持つ価値も上がります。AI化の恩恵を受けながら、その知識がどこかの学習データに使われていないかを問い続ける姿勢が必要です。
ある大手製薬メーカーとの取り組みでは、R&D部門からの要望として「AIを活用して研究の効率を上げたいが、化合物のデータは社外に一切出せない」という条件が最初から提示されました。この案件がパブリッククラウドのAIでは対応できないと判断し、ソブリン環境でのローカルLLM(大規模言語モデル)活用を前提に設計を進めることになったのは、ごく自然な流れでした。
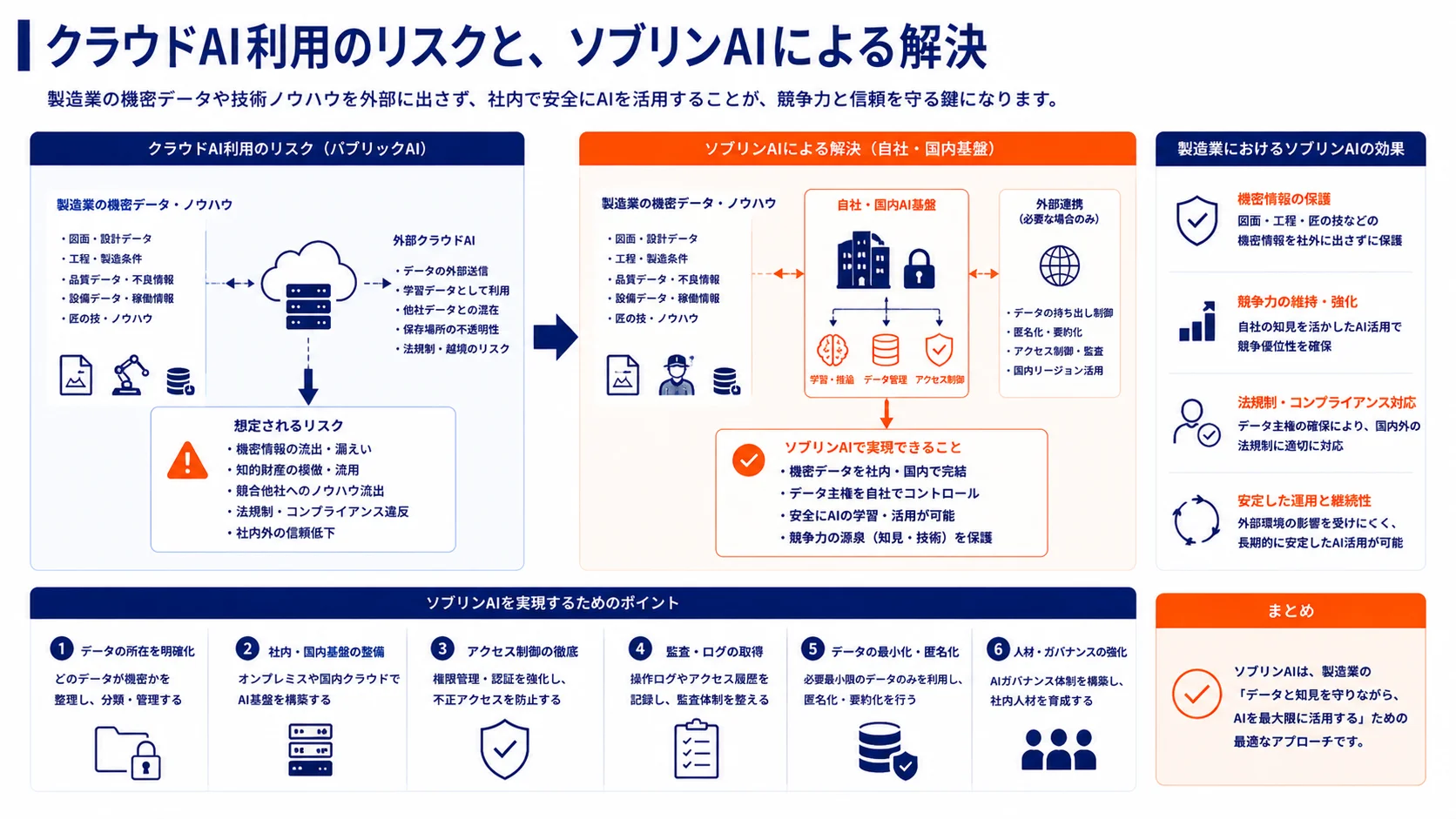
ChatGPTに工場の生産データを入れてはいけない理由
「でも、うちの社員はもうChatGPTを業務で使っていますよ」——現場に入ると、この話を頻繁に聞きます。
問題は、ChatGPTやその他のパブリックAIサービスがデータを「学習」に使うかどうかではありません。それ以前の問題として、データが自社の管理外のサーバーに送信されるという事実そのものにリスクがあります。
具体的にどういうことが起きうるか。3つのシナリオを挙げます。
シナリオ1:意図せない情報漏洩。メールの返信文をAIに書かせようとして、文脈として顧客との契約条件や納期交渉の内容を貼り付けてしまう。個人情報だけでなく、営業上の機密が含まれるケースです。
シナリオ2:不正アクセスリスク。利用しているAIサービス事業者がサイバー攻撃を受けた場合、そこに送信されたデータが漏洩する可能性があります。データを「送らない」ことが最大の防御です。
シナリオ3:ガバナンスの不透明化。AIサービスのプライバシーポリシーや利用規約は頻繁に変更されます。「今は学習に使われていない」という状態が将来も保証されるわけではありません。
誤解のないように申し上げると、これはパブリックAIを使うなということではありません。どのデータをどのサービスに入力してよいかを組織として判断するプロセスを設計することが、今最も求められているということです。
私たちが製造業のお客様に最初に提案するのが「AIデータ分類」です。自社が扱うデータを「パブリックAIでも問題ないもの」「社内ガイドラインの下で利用可」「原則クラウド外でのみ処理」の3段階に分類する。この分類があるだけで、現場の判断基準が明確になります。
パブリックAIとソブリンAI——何が違うのか
混乱しやすいので整理します。
| 観点 | パブリックAI | ソブリンAI |
|---|---|---|
| データの場所 | 提供企業のサーバー(海外が多い) | 自社・国内クラウド・オンプレミス |
| コスト | 低い(従量課金) | 高い(インフラ投資が必要) |
| セキュリティ | 提供企業の規約に依存 | 自社で設計・管理 |
| カスタマイズ性 | 低い | 高い(自社データで追加学習可) |
| 機密データへの対応 | 原則不可 | 可(設計次第) |
| 適合法令 | 各国規制への対応はサービスによる | 国内法令への準拠を自社で設計 |
ただし、この表を見て「ソブリンAIのほうが優れている」と結論するのは早計です。コストと管理負担の観点では、パブリックAIのほうが明らかに優位です。初期投資なしで使え、維持管理の手間もほぼかかりません。重要なのは用途に応じた使い分けです。
社内の汎用業務(メール作成、会議録の要約、資料のたたき台作成)にはパブリックAIで十分です。一方、R&Dデータの解析、品質管理ロジックへの学習、設計ノウハウのナレッジ化といった機密性の高い業務には、ソブリン環境が必要になります。
私たちが現場でよく使う判断軸は「もしそのデータが外部に出たとき、競合優位性に影響するか」です。影響するなら、ソブリン環境での処理を検討する価値があります。
2026年、日本でのソブリンAI最新動向
日本でのソブリンAIをめぐる動きは、2026年に入って加速しています。
AnthropicとNEC、三井住友FG・大和証券など金融8社がAI活用で連携したことが2026年6月に発表されました。金融分野でのAI活用は機密性への要求が特に高く、国内パートナー(NEC)とグローバルAI企業(Anthropic)が組み、データ主権を確保しながら高度なAI活用を実現しようとする動きです。製造業においても同様のモデルが今後広がる可能性が高いと見ています。
さくらインターネットは国産GPUクラウド「高火力」を提供し、LLMの学習・推論を国内で完結させる環境を整えています。NTTも「tsuzumi」という日本語特化の国産LLMを開発・提供しています。政府もデジタル庁を中心に「ガバメントAI」の整備を進めており、「源内」という名のAIプラットフォームが行政内で稼働し始めています。
これらの動きが示しているのは、「ソブリンAIは大企業と政府だけの話」ではなくなりつつあるということです。クラウドインフラのコストが下がり、国産LLMの精度が上がることで、中小製造業でも現実的な選択肢になってきています。
中小製造業が今すぐ取れる3ステップ
「ソブリンAIと言っても、うちは中小企業なのでオンプレミスサーバーを立てる余力はない」——この声は現場でよく聞きます。ただ、完全なオンプレミス構築は1つの選択肢に過ぎません。実態に合わせたアプローチを3段階で提示します。
STEP1: AIデータ分類表を1枚作る
費用ゼロで今日からできます。自社が扱うデータを「パブリックAI可」「社内ガイドライン下で可」「クラウド外のみ」の3段階に分類して一覧化するだけです。これを全社で共有することで、現場担当者が独自にAIツールを使い始めても「このデータは外に出せない」という判断ができるようになります。
STEP2: 社内ドキュメントのRAG構築を国内環境で
次の段階として、社内のマニュアル・設計書・議事録を検索できる「社内AI」を国内クラウドで構築します。RAG(検索拡張生成)という仕組みを使うと、LLMに社内文書を読み込ませて質問に答えさせることができます。この構成では、元データは自社サーバーか国内クラウドに置いたままにでき、海外サービスへのデータ送信を最小化できます。私たちが中堅製作所向けに構築したナレッジプラットフォームもこの構成で、音声から自動生成されるFAQや、メール解析によるナレッジ抽出が稼働しています。
STEP3: 機密業務に限定してローカルLLMを活用する
R&Dデータや設計データなど最高機密の業務については、完全オフライン環境のローカルLLMを検討します。近年、LlamaやMistralなどのオープンソースモデルが急速に実用域に達しており、クラウドを使わずに社内サーバー上で動かすことが現実的になっています。大手通信企業との協業でも、このローカルLLM×ソブリン環境のパッケージ展開が始まっています。
AI-Pathが見てきた「データ主権なき導入」の末路
FDEとして現場に入り続けて見えてくるのは、「まず試してみよう」でAI活用を始めた企業が、半年後に課題を抱えているパターンです。
典型的なのが、部門ごとに異なるAIツールが乱立して、どのデータがどこに送られているか誰も把握できなくなるケースです。これは「野良アプリ問題」と私たちが呼んでいる現象で、VibeCodingが普及した組織での課題としても指摘されています。データ主権の観点から見ると、野良アプリ問題は単なる管理の乱れではなく、機密データの流出経路が無数に生まれているリスクでもあります。
もう1つのパターンは、「とりあえずAzure OpenAIにしたので安全」と思っているケースです。確かに、AzureのOpenAIサービスはプロンプトをモデルの学習に使わないポリシーを持っています。ただし、これはMicrosoft社のサーバーにデータが送られるという事実は変わりません。業種・データの性質によっては、それだけで規制上の問題になります。
「どこで処理されるか」を問うことが、ソブリンAIの入口です。これが明確でないまま進めてしまうと、後から設計し直すコストが発生します。
よくある質問
Q: ローカルLLMはクラウドのAIと比べて性能が低いですか?
2026年現在、用途を限定すれば実用レベルに達しています。汎用的な質問応答はクラウドのAIのほうが高性能ですが、自社データで追加学習(ファインチューニング)を施すことで、特定業務の精度は逆にクラウドを上回ることもあります。R&Dの文献検索や品質管理の判定支援など、領域を絞った用途であれば十分な選択肢です。
Q: コストはどのくらいかかりますか?
STEP1(データ分類表の作成)はゼロ円です。STEP2(社内RAG)は国内クラウドを使えば月額数万円から始められます。STEP3(ローカルLLM)は必要なGPUサーバーの調達が主なコストで、中小企業であれば月額リース10〜30万円程度の試算になることが多いです。
Q: 既存のAI活用の取り組みを全部見直す必要がありますか?
いいえ。まず「今使っているAIサービスに何のデータを入力しているか」を可視化することが先決です。可視化したうえで、機密性の高いデータだけ扱いを変える——このアプローチが現場の負荷を最小化しながらリスクを下げる現実解です。
Q: 個人情報保護法の2026年改正とソブリンAIはどう関係しますか?
2026年の改正では、AIによる個人情報の利用・第三者提供に関する規定が強化されています。特に、AIサービス事業者が提供者のデータを学習に使う場合の同意取得要件が厳しくなっています。ソブリン環境での運用は、こうした規制への対応という観点でも有効です。
まず試すなら
1. 今使っているAIツールとデータの棚卸しをする
社内で使用中のAIサービス一覧と、そこに入力している情報の種類を書き出してください。「意外なところに機密データが入っていた」という発見が、多くのケースで出てきます。これを確認するだけで、次のアクションが自然と見えてきます。
2. AIデータ分類表を1枚作ってみる
全社展開は後でいい。まず自部門の業務データについて「外部AIで使えるもの」「使えないもの」を分類してみてください。この1枚があるだけで、現場の判断基準が揃います。
3. AI-Pathの無償業務プロセス診断(BPR)を活用する
自社の業務でどのデータをAIで活用できるか、どこにリスクがあるか、ソブリン環境が本当に必要な業務はどこかを一緒に整理します。FDEとして現場に入る私たちが、現実的な構成を提案します。
AI-Pathでは、製造業の現場に入るFDEが**無償の業務プロセス診断(BPR)**を実施しています。自社のどの業務・データにAIを使えるか、どこにデータ流出リスクがあるか、ソブリン環境が本当に必要な領域はどこかを、1時間程度の対話で整理します。「まず何から手をつければいいかわからない」という状態からでも、具体的な次の一手が見えるようにします。
まずは無償の業務診断で、自社のAI活用とデータ主権の全体像を整理しませんか。お気軽にご連絡ください。
筆者プロフィール
櫻井文雄 / 株式会社AI-Path 代表
関西大学法学部法律学科卒業。財務コンサルティング会社(エフアンドエム)、外資系生保営業(Prudential)でコンサルティング営業の経験を積んだ後、起業し様々な企業のCTO/CMOを歴任。その後、デロイトトーマツコンサルティング(Big4)、ABEJA(AI研究開発の国内リーディングカンパニー)にて官公庁・製造業・金融業・小売業・不動産業を中心に延べ20社以上のDX推進や業務システム刷新をPM/SMとしてリード。利用者目線での現場の課題解決にフォーカスしたものづくりに拘り、導入ではなく「定着化」を目的とした伴走型のプロジェクト推進・システム導入を得意とする。 2025年にAI駆動開発(VibeCoding)と出会い、より多くの人・企業に価値提供するためにAI-Pathを創業。
参考リンク
AnthropicとNEC、金融8社とAI活用で連携 三井住友FG、大和証券など(ITmedia AI+) — 国内企業がソブリン環境でのAI活用を模索する最新事例。
ソブリンAIとは?意味や特徴・課題・日本や海外での取り組みも紹介(AISmiley) — ソブリンAIの3層構造(Data・Compute・Model)をわかりやすく解説した概説記事。
ソブリンAI時代の新戦略が開く日本企業の未来(Teradata) — 日本企業がソブリンAI戦略を構築するための実務的視点。
関連コラム

製造業の見積もり・原価管理はなぜ属人化するのか——AIで「数字の勘」を資産に変える進め方
過去の見積もり条件も、複数工場をまたぐ原価配賦も、担当者の記憶の中に閉じていませんか。特注プラントメーカーやシャッターメーカーの現場の声をもとに、AIで数字の判断基準を組織の資産に変える進め方を、FDEとして現場に入ってきた経験から整理します。

製造業の技能継承をAIで仕組み化する——暗黙知を「聞き出すAI」で終わらせない進め方
経済産業省のGENIAC-PRIZEや業界横断組織の発足など、2026年は「暗黙知のAI化」が政策レベルで動き出した年です。しかしAIに聞かせるだけでは技能は継承されません。私たちがFDEとして現場に入ってきた経験から、技能継承を「使われる仕組み」に変える設計を整理します。

製造業でAI導入が失敗する本当の理由——PoC止まりを脱した現場が実践した定着化の3ステップ
製造業のAI導入はPoCで成功しても7割が本番運用に至らないと言われます。技術の問題ではなく、運用設計・現場定着・継続改善の3つの分岐点をどう超えるか。現場伴走で見えた定着化の実践論です。